We have spoken many times about the vast quantity of data which exists in the auto parts sector and the fact that new data is constantly appearing.
But, when we focus on specific application segments like the industrial, agricultural or marine sectors, among others, the complexity deepens until neither the common data structuring mechanisms, nor the traditional product analysis tools we use, can help us out.
Obviously, in order to analyse any application segment, we need to have data on all existing products.
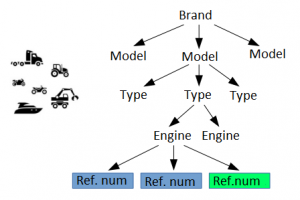
Companies, whether manufacturers or distributors, create their own reference numbers codifications used to define the universe of products they want to work with and/or analyse. These individual codifications organise the thousands of existing products and millions of OE, OEM and IAM reference numbers through two distinct data structures:
1) Applications. The company’s own codes are associated with a standard vehicle park definition, where we can also find links to other OE, OEM and IAM references.
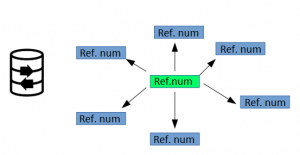
2) Equivalences. The company’s own codes are linked to the OE, OEM and IAM references intended to be organised.
Most companies maintain both data structures, although some only define equivalences. Either way, an enormous quantity of human resources and time must be employed to keep these data structures up to date.
These data structures are incredibly important, as they are used continually in all search and analysis processes performed at every company.
But, what structural problems do these data structures present when we want to analyse very specific application segments like the industrial, agricultural or marine sectors?
1) Applications
There is no universal vehicle park which defines all applications. This makes it impossible to detect all existing products via applications.
We fail to know the application of many reference numbers, which means many products cannot be analysed based on their applications.
A single reference number may be associated with multiple applications and a single application with multiple reference numbers, which produces many imprecisions.
2) Equivalences
No existing codification relates more than 60% of the total OE/OEM/IAM reference numbers on the market. Thus, the analysis based on a single codification is always limited.
Every codification uses different reference number grouping criteria, which makes it enormously difficult to combine them in an effort to widen the analysis.
For all these reasons, obviously, then, all companies have a vision of data which is:
INCOMPLETE, IMPRECISE AND COMPLEX
And now that we know the limitations of these data structures when it comes to analysing the market, we might want to ask ourselves: is there any mechanism that could help us analyse all existing products on the market in a COMPLETE, PRECISE and SIMPLE way?
The answer is, yes. Factory Data has designed a disruptive technology capable of solving these structural data problems.
The solution consists in separating ourselves completely from the application data structures, which we have already identified as being not only imprecise but, above all, incomplete, and replacing them with a method that combines the equivalence-based data structures from all the main providers in the market via an proprietary clustering algorithm, thereby supplying the most complete vision possible of all existing knowledge.
This totally new data structure enables us to offer disruptive services like demand analysis, calculated with maximum precision, on products from any application segment but, in particular, for the industrial, agricultural and marine sectors.
In the next article we’ll explain in more detail how this data structure works and why it provides us with a vision of the market that is: COMPLETE, PRECISE and SIMPLE.